
ForgeRock Directory Services 7.2 was and will be the last release of ForgeRock products that I’ve managed. It was finished when I left the company and was released to the public a few days after. Before I dive into the changes available in this release, I’d like to thank the amazing team that produced this version, from the whole Engineering team led by Matt Swift, to the Quality engineering led by Carole Forel, the best and only technical writer Mark Craig, and also our sustaining engineer Chris Ridd who contributed some important fixes to existing customers. You all rock and I’ve really appreciated working with you all these years.
So what’s new and exciting in DS 7.2?
First, this version introduces a new type of index: Big Index. This type of index is to be used to optimize search queries that are expecting to return a large number of results among an even much larger number of entries. For example, if you have an application that searches for all users in the USA that live in a specific state. In a population of hundreds of millions users, you may have millions that live in one particular state (let’s say Ohio). With previous versions, searching for all users in Ohio would be unindexed and the search if allowed would scan the whole directory data to identify the ones in Ohio. With 7.2, the state attribute can be indexed as a Big Index, and the same search query would be considered as indexed, only going through the reduced set of users with that have Ohio as the value for the state attribute.
Big Indexes can have a lesser impact on write performances than regular indexes, but they tend to have a higher on disk footprint. As usual, choosing to use a Big Index type is a matter of trade-of between read and write performances, but also disk space occupation which may also have some impact on performances. It is recommended to test and run benchmarks in development or pre-production environments before using them in production.
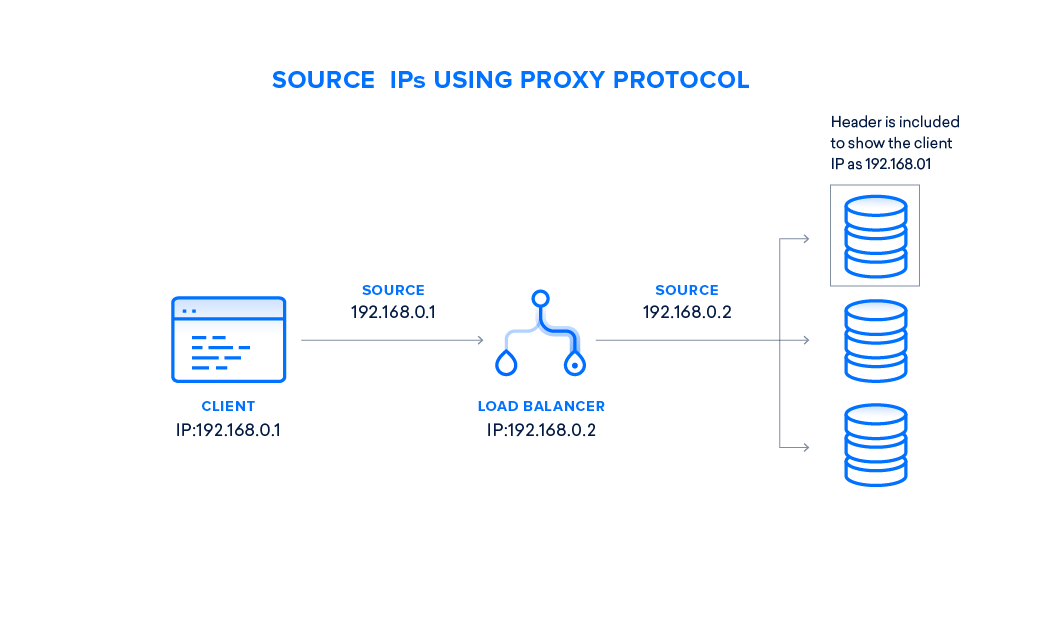
The second significant new feature in 7.2 is the support of the HAProxy Protocol for LDAP and LDAPS. When ForgeRock Directory Services is deployed behind a software load-balancer such as HAProxy, NGINX or Kubernetes Ingress, it’s not possible for DS to know the IP address of the Client application (the only IP address known is the one of the load-balancer), therefore, it is not possible to enforce specific access controls or limits based on the applications. By supporting the HAProxy Protocol, DS can decode a specific header sent by the load-balancer and retrieve some information about the client application such as IP address but also some TLS related information if the connection between the client and the load-balancer is secured by TLS, and DS can use this information in access controls, logging, limits… You can find more details about DS support of the Proxy Protocol in DS documentation.
In DS 7.2, we have added a new option for securing and hashing passwords: Argon2. When enabled (which is the default), this allows importing users with Argon2 hashed passwords, and letting them authenticating immediately. Argon2 may be selected as well as the default scheme for hashing new passwords, by associating it with a password policy (such as the default password policy). The Argon2 password scheme has several parameters that control the cost of the hash: version, number of iterations, amount of memory to use and parallelism (aka number of threads used). While Argon2 is probably today the best algorithm to secure passwords, it can have a very big impact on the server’s performance, depending on the Argon2 parameters selected. Remember that DS encrypts the entries on disk by default, and therefore the risk of exposing hashed passwords at rest is extremely low (if not null).
Also new is the ability to search for attributes with a DistinguishedName syntax using pattern matching. DS 7.2 introduces a new matching rule named distinguishedNamePatternMatch (defined with the OID 1.3.6.1.4.1.36733.2.1.4.13). It can be used to search for users with a specific manager for example with the following filter “(manager:1.3.6.1.4.1.36733.2.1.4.13:=uid=trigden,**)” or a more human readable form “(manager:distinguishedNamePatternMatch:=uid=trigden,**)”, or to search for users whose manager is part of the Admins organisational unit with the following filter “(manager:1.3.6.1.4.1.36733.2.1.4.13:=*,ou=Admins,dc=example,dc=com)”.
ForgeRock Directory Services 7.2 includes several minor improvements:
- Monitoring has been improved to include metrics about index use in searches, and access logs now contain information about the proc entry’s size (the later is also written in the access logs).
- The index troubleshooting attribute “DebugSearchIndex” output has been revised to provide better details for the query plan.
- Alert notifications are raised when backups are finished.
- The REST2LDAP service provides several enhancements making several queries easier.
As with every release, there has been several performances optimizations and improvements, many minor issues corrected.
You can find the full details of the changes in the Release Notes.
I hope you will enjoy this latest release of ForgeRock Directory Services. If not, don’t reach out to me, I’m no longer in charge. 😀

 Until recently, the only way to store a JSON object to an LDAP directory server, was to store it as string (either a Directory String i.e a sequence of UTF-8 characters, or an Octet String i.e. a blob of octets).
Until recently, the only way to store a JSON object to an LDAP directory server, was to store it as string (either a Directory String i.e a sequence of UTF-8 characters, or an Octet String i.e. a blob of octets).


 As the legacy Sun product has reached its end of life, many companies are looking at migrating from Sun Directory Server Enterprise Edition [SunDSEE] to
As the legacy Sun product has reached its end of life, many companies are looking at migrating from Sun Directory Server Enterprise Edition [SunDSEE] to 



 Time flies…
Time flies…  David Goodman started the conference with a
David Goodman started the conference with a 
 Starting Wednesday with tutorials, and the main conference on Thursday and Friday, the
Starting Wednesday with tutorials, and the main conference on Thursday and Friday, the  A few years ago I had the pleasure to work with Rajesh Rajasekharan at Sun. He was an efficient trainer on Sun products and especially on Sun Directory Server. He recently joined ForgeRock and has started a
A few years ago I had the pleasure to work with Rajesh Rajasekharan at Sun. He was an efficient trainer on Sun products and especially on Sun Directory Server. He recently joined ForgeRock and has started a 